dis9034-2024-1
clase-15
Investigación sobre Speech p5
Speech P5 - Creador Luke DuBois
la web está en https://idmnyu.github.io/p5.js-speech/
p5.speech: Es una extensión de p5 para proporcionar una funcionalidad Web de síntesis y reconocimiento. Consta de dos clases de objetos uno es p5.Speech y el otro p5.SpeechRe. Junto con funciones de acceso para hablar y escuchar texto, cambiar parámetros como diferentes voces de síntesis, modelos de reconocimiento, entre otros. Esta herramienta da acceso simple y claro a las APIs de habla web, permitiendo la creación de bosquejos sencillos que pueden hablar y escuchar.
El reconocimiento de voz requiere el lanzamiento desde un servidor usando HTTPS (por ejemplo, usando un servidor python en una máquina local).
HTTPS: Es el protocolo de transferencia de hipertexto seguro, se caracteriza por ser el principal protocolo utilizado para enviar datos entre un navegador web y un sitio web de forma segura.
Web Speech API permite incorporar datos de voz en aplicaciones web.
La API Web Speech tiene dos partes
-
SpeechSynthesis (Texto a voz): Es un componente de texto a voz que permite a los programas leer su contenido de texto a traves del sintetizador de voz predeterminado del dispositivo, por lo general
-
SpeechRecognition (Reconocimiento de voz asincrónico): Es una interfaz que permite reconocer el contexto de voz desde una entrada de audio de un dispositivo y responder adecuadamente. Usualmente utiliza el controlador de eventos disponible para detectar cuando es ingresada la voz a través del micrófono del dispositivo, ya sea un smartphone, pc, dispositivo de audio, etc.
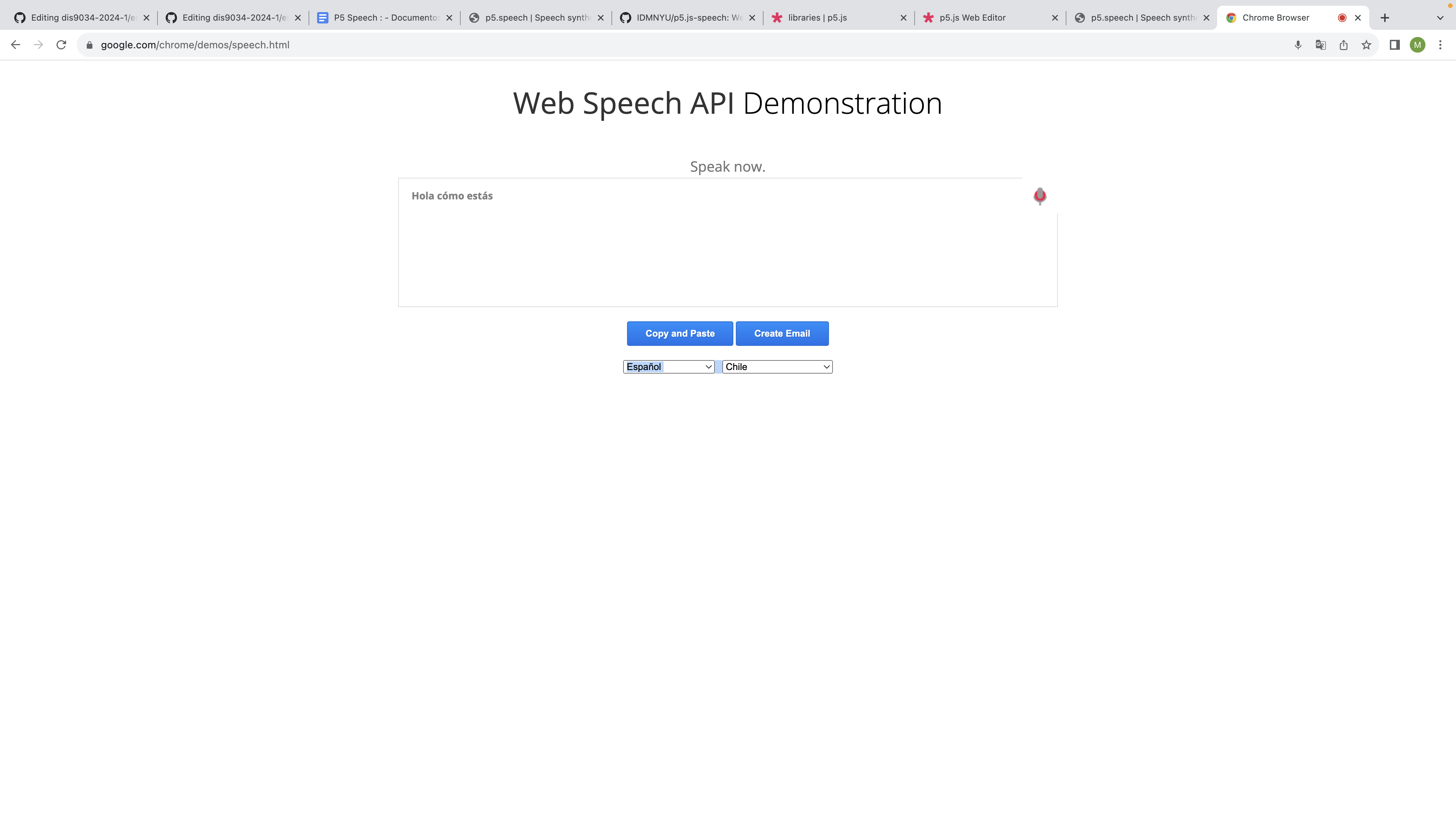
- Web speech API Demonstration: Esta web es un ejemplo del funcionamiento de speech. En ella puedes hablar mediante el micrófono de tu dispositivo (ya sean oraciones largas o cortas o también pausadas) y lo que digas será transcrito con este speech, también cuenta con la opción de cambiar el idioma como gustes y seleccionar tu país. -
- link de web speech demostration
Ejemplos de speech funcionales
-
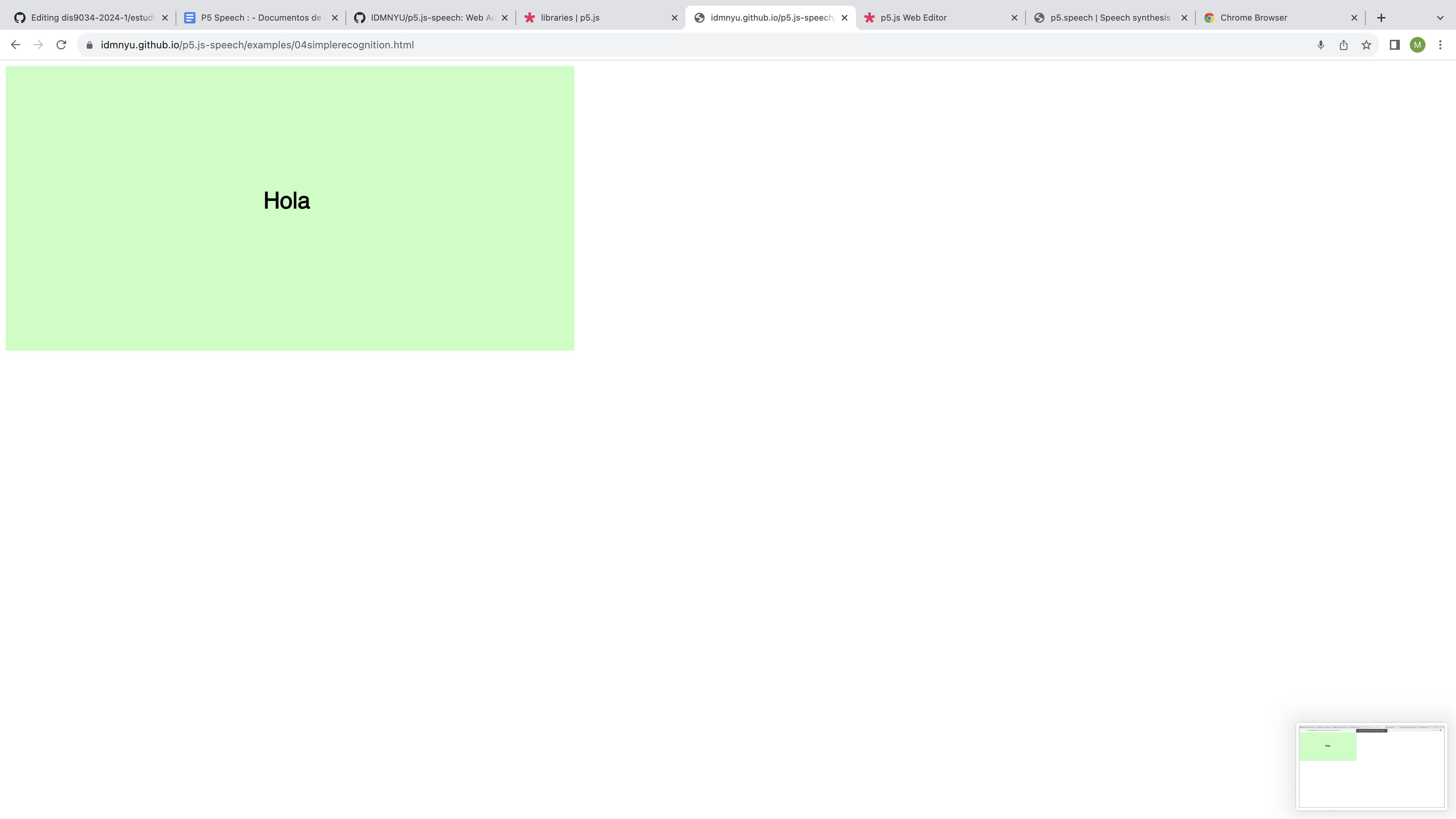
En esta web puedes hablar mediante el micrófono de tu dispositivo y lo que digas será transcrito con este speech. Acepta palabras acotadas y va de una palabra en una. También al transcribir la palabra escuchada el canvas de fondo cambia a color verde.
interacción:
resultado:
-
En esta web puedes presionar en diferentes lugares del canvas y sonara un sonido o palabra, según el lugar que oresiones este cambiara su tono o palabra / expresión.
Líneas de código
p5.Speech
- default_voice: argumento opcional para establecer la voz por defecto del sintetizador por número (ver listVoices()) o por nombre. métodos
- cancel(): cancela silenciosamente la locución actual y borra las locuciones en cola.
- listVoices(): sentencia de depuración. Lista las voces de síntesis disponibles en la consola JavaScript.
- pause(): pausa la locución actual. Se activará la llamada de retorno onPause().
- resume(): reanuda la locución actual. Se activará la llamada de retorno onResume().
- setLang(language): establece el intérprete de idioma para la voz del sintetizador. El argumento es BCP-47; por defecto es “en-US”.
- setPitch(pitch): establece el tono de reproducción de la voz sintetizada entre 0,01 (muy bajo) y 2,0 (muy alto). Por defecto es 1.0; no es compatible con todas las combinaciones de navegador y sistema operativo.
- setRate(rate): establece la velocidad de producción del habla de 0,1 (muy lenta) a 2,0 (muy rápida). Por defecto es 1.0; no es compatible con todas las combinaciones de navegador y sistema operativo.
- setVoice(voice): establece la voz del sintetizador por número (ver listVoices()) o por nombre; equivalente al parámetro default_voice pasado con el constructor.
- setVolume(volume): establece el volumen del sintetizador entre 0,0 (silencio) y 1,0 (por defecto=volumen máximo).
- speak(utterance): ordena al sintetizador que pronuncie la cadena codificada en utterance. Dependiendo de la propiedad de interrupción, las llamadas adicionales a speak() se pondrán en cola después o interrumpirán el habla que se está sintetizando activamente. Cuando comienza la síntesis, se activa la llamada de retorno onStart(); cuando termina, se activa la llamada de retorno onEnd().
- stop(): detiene la expresión actual. Se activará la llamada de retorno onEnd(). –propiedades
- interrupt: booleano para establecer si el método speak() interrumpirá (true) o se pondrá en cola después (false = por defecto) del enunciado que se esté sintetizando en ese momento.
- onEnd: función que establece la llamada de retorno que se activará cuando finalice un enunciado.
- onLoad: función que activa la llamada de retorno cuando se cargan las voces de síntesis.
- onPause: función que activa la llamada de retorno cuando se pausa una locución.
- onResume: función que activa la llamada de retorno cuando se reanuda una locución.
- onStart: función que activa la llamada de retorno cuando se inicia la síntesis.
p5.SpeechRec
- default_language: argumento opcional para establecer el idioma / región BCP-47 por defecto para el sistema de reconocimiento de voz. n.b. p5.SpeechRec() no funcionará a menos que se utilice un servidor seguro (HTTPS). si el navegador nunca te pide que permitas el acceso a tu micrófono, eso es lo primero que debes solucionar. métodos
- start(): ordena al sistema de reconocimiento de voz que comience a escuchar. utilice el modo continuo en lugar de múltiples llamadas a start() para múltiples tokens de reconocimiento dentro del mismo sitio. –propiedades
- continuous: booleano para establecer si el motor de reconocimiento de voz dará resultados continuamente (true) o sólo una vez (false = por defecto).
- p.d. continuous se establece por defecto en “false” para proteger la privacidad de los usuarios: establecer continuous en “true” crea un micrófono abierto persistente entre el dispositivo de navegación de los usuarios y el motor de reconocimiento de voz basado en la nube para su navegador (es decir, Google).
- p.p.s.: además de ser potencialmente una mala decisión desde el punto de vista ético, el modo continuo es poco fiable: la tubería de audio entre el navegador y el servidor de reconocimiento se rompe con bastante facilidad, especialmente con los navegadores que no son Chrome. si realmente quieres algo que reconozca continuamente el habla, configura una meta-refresca en tu página para que se recargue cada par de minutos.
- interimResults: booleano para establecer si el motor de reconocimiento de voz dará resultados parciales más rápidos (true) o esperará a que el hablante haga una pausa (false = por defecto).
- onEnd: función que activa la llamada de retorno cuando finaliza el reconocimiento de voz.
- onError: función que activa una llamada de retorno cuando se produce un error en el cliente al grabar y transmitir la voz.
- onResult: función que activa la llamada de retorno cuando el motor de síntesis informa de un resultado.
- onStart: función que activa la llamada de retorno cuando comienza el reconocimiento del habla.
- resultConfidence: valor flotante (0,0-1,0) que representa el nivel de confianza del sintetizador de voz en que resultString es lo que realmente ha dicho el usuario.
- resultJSON: objeto JSON que contiene un conjunto completo de datos devueltos por el sistema de reconocimiento de voz.
- resultString: Cadena que contiene el habla detectada más recientemente.
- resultValue: valor booleano que contiene un indicador de estado notificado por el servidor (true = habla reconocida correctamente).
Estas descripciones fueron citadas y traducidas desde este link de github de IDMNYU https://idmnyu.github.io/p5.js-speech/
Fuentes utilizadas:
- link de web de datos con respecto a speech: https://developer.mozilla.org/en-US/docs/Web/API/Web_Speech_API
- link de web de datos con respecto a speech https://idmnyu.github.io/p5.js-speech/